Inteligencia artificial en enfermedades crónicas: análisis cienciométrico y su implicación en la toma de decisiones clínicas
Artificial inteligence in chronic diseases: a scientometric analysis and its implications for clinical decision-making
Introducción: la inteligencia artificial ha transformado la investigación clínica moderna, particularmente en el abordaje de las enfermedades crónicas no transmisibles. El crecimiento masivo y desestructurado de publicaciones científicas actuales imponen un desafío crítico para la actualización constante y la síntesis de evidencia científica por parte del profesional médico. Objetivo: describir desde una perspectiva cienciométrica la evolución, estructura intelectual y tendencias de la producción científica global sobre inteligencia artificial aplicada a enfermedades crónicas no transmisibles. Métodos: se realizó un estudio descriptivo y transversal utilizando la base de datos Scopus, año 2024. Se emplearon herramientas avanzadas de minería de datos como VOSviewer y el paquete Bibliometrix de R para procesar 9181 documentos, evaluando indicadores de producción, impacto científico y redes de colaboración internacional. Resultados: se identificó una tasa de crecimiento anual sostenida, destacando un índice h de 47 para el corpus analizado. China y Estados Unidos se consolidan como las potencias líderes en producción y citación. El análisis de clústeres temáticos reveló un marcado predominio del aprendizaje profundo aplicado a la oncología, la cardiología y el diagnóstico por imagen de alta precisión, evidenciando una transición hacia la medicina personalizada. Conclusiones: la saturación informativa y la complejidad tecnológica exigen un cambio profundo en el paradigma educativo. Los hallazgos subrayan la necesidad de integrar formalmente la alfabetización de datos en la formación médica. Este enfoque permitirá fortalecer las competencias del especialista, facilitando la toma de decisiones clínicas y quirúrgicas optimizados mediante modelos de inteligencia artificial, garantizando una práctica médica más precisa, eficiente y segura.
Introduction: Artificial intelligence has transformed modern clinical research, particularly in the management of non-communicable chronic diseases. The massive and unstructured growth of current scientific publications poses a critical challenge for the continuous updating and synthesis of scientific evidence by medical professionals. Objective: To describe, from a scientometric perspective, the evolution, intellectual structure, and trends of global scientific production regarding artificial intelligence applied to non-communicable chronic diseases. Methods: A descriptive and cross-sectional study was conducted using the Scopus database for the year 2024. Advanced data mining tools such as VOSviewer and the R Bibliometrix package were used to process 9,181 documents, evaluating production indicators, scientific impact, and international collaboration networks. Results: a sustained annual growth rate was identified, with a notable h-index of 47 for the analyzed corpus. China and the United States have consolidated their positions as the leading powers in production and citations. The thematic cluster analysis revealed a marked predominance of deep learning applied to oncology, cardiology, and high-precision diagnostic imaging, evidencing a transition toward personalized medicine. Conclusions: Information saturation and technological complexity demand a profound shift in the educational paradigm. The findings underscore the need to formally integrate data literacy into medical training. This approach will strengthen specialists' competencies, facilitating clinical and surgical decision-making optimized through artificial intelligence models, thus ensuring a more precise, efficient, and safe medical practice.
Introducción
La inteligencia artificial (IA) en salud ha transitado desde sistemas expertos basados en reglas hacia arquitecturas modernas de aprendizaje automático y aprendizaje profundo capaces de procesar imágenes médicas, datos ómicos y registros electrónicos para tareas de clasificación, segmentación y predicción clínica. Este avance ha sido impulsado por la disponibilidad de grandes volúmenes de datos biomédicos, mejoras en capacidad computacional y la proliferación de librerías y plataformas que facilitan el desarrollo reproducible de modelos. Tales desarrollos han generado modelos con buen rendimiento en estudios retrospectivos y han suscitado debates críticos sobre interpretabilidad, sesgo y reproducibilidad, por lo que un análisis sistemático de la literatura permite cartografiar tendencias, identificar vacíos y priorizar líneas de investigación para una implementación responsable.[1], [2]
Conceptualmente, la IA agrupa técnicas que automatizan tareas cognitivas; el aprendizaje automático comprende algoritmos que aprenden de datos para predecir o clasificar, y el aprendizaje profundo usa redes neuronales profundas para representar relaciones complejas en imágenes y secuencias genómicas. Estas distinciones permiten clasificar estudios en supervisados, no supervisados y por refuerzo, y ayudan a evaluar limitaciones como la necesidad de datos etiquetados, interpretabilidad y riesgo de sobreajuste. La precisión estadística de un modelo no garantiza utilidad clínica: diferencias demográficas, prácticas de adquisición de datos y variabilidad en la atención pueden afectar la generalizabilidad, por lo que la validación externa y ensayos de implementación son esenciales para confirmar beneficio real en salud.[3]
El antecedente histórico muestra etapas claras: primeros sistemas expertos, expansión con el aprendizaje automático (ML, por sus siglas en inglés Machine Learning) clásico y la revolución reciente con aprendizaje profundo (DL, por sus siglas en inglés Deep Learning) y disponibilidad de datos óptimos. En la última década, la proliferación de datasets públicos y competiciones empujó comparaciones entre modelos, y la difusión de preprints aceleró la comunicación científica antes de la revisión por pares. Esa rapidez ha generado beneficios y desafíos: aumento del volumen de evidencia, diversidad metodológica y tensión entre velocidad y rigor científico. Asimismo, áreas como la oncología han sido favorecidas por datos digitales y biomarcadores maduros, promoviendo concentración temática y la necesidad de evaluar reproducibilidad en poblaciones diversas.[4]
La importancia de estudiar la producción científica radica en su capacidad para orientar políticas, priorizar financiamiento y focalizar esfuerzos de validación que permitan la transferencia clínica segura. Modelos validados pueden mejorar cribados, estratificación de riesgo y decisiones terapéuticas, pues reducen la carga de enfermedad y optimizan recursos sanitarios. En contraste, la ausencia de estándares de reporte puede conducir a implementaciones prematuras y desigualdades si los modelos reproducen sesgos poblacionales o estructurales. Un mapeo riguroso de 2024 identifica áreas consolidadas y vacíos metodológicos, y facilita recomendaciones regulatorias y de gobernanza que promuevan adopciones responsables y equitativas.(5-7) Por todo lo anterior se realiza la presente investigación con el objetivo de describir desde una perspectiva cienciométrica la evolución, estructura intelectual y tendencias de la producción científica global sobre IA aplicada a enfermedades crónicas no transmisibles (ECNT).
Métodos
Se realizó un estudio bibliométrico descriptivo y transversal utilizando la base de datos Scopus para el año 2024 sobre la producción científica relacionada con la inteligencia artificial aplicada a la predicción y diagnóstico de ECNT.
Las publicaciones fueron recuperadas de la base de datos Scopus el 20 de agosto de 2025, sin establecer limitación temporal. Se seleccionó esta base por su amplia cobertura internacional y multidisciplinaria, lo que garantiza una representación sólida de la literatura científica en el área de la inteligencia artificial aplicada a la salud.
La estrategia de búsqueda empleó los siguientes términos:
[ TITLE-ABS-KEY ( "artificial intelligence" OR "machine learning" OR "deep learning" OR "neural network" OR "predictive model" OR "AI" ) AND TITLE-ABS-KEY ( predict* OR prevention OR preventative OR preventive OR prognos* OR "early diagnosis" OR "risk assessment" ) AND TITLE-ABS-KEY ( treatment OR therapy OR managment ) AND TITLE-ABS-KEY ( "chronic disease" OR "noncommunicable diseases" OR diabetes OR hypertension OR "cardiac disease" OR "heart disease" OR cancer OR copd OR "asthma" OR "chronic kidney" OR obesit* ) ] AND [ LIMIT-TO ( PUBYEAR , 2024 ) ].
Esta estrategia integral se diseñó para capturar todas las publicaciones relevantes sobre el uso de la inteligencia artificial en la predicción, prevención, diagnóstico y tratamiento de enfermedades crónicas no transmisibles.
Para cada registro se extrajo información bibliográfica y de citación, incluyendo número de publicaciones, citas totales, títulos, autores, instituciones, países o afiliaciones, resumen, palabras clave y revistas. Los registros se exportaron en formato BibTeX y fueron depurados para eliminar duplicados.
Análisis de datos:
El análisis bibliométrico y de mapeo del conocimiento se realizó utilizando las herramientas VOSviewer (v1.6.20), CiteSpace (v6.3.R1) y el paquete R-bibliometrix (v5.1.0).
VOSviewer se empleó para construir redes de colaboración, coautoría, co-citación y coocurrencia de palabras clave, lo que permitió visualizar clústeres temáticos y mapas de densidad.
Harzing’s Publish or Perish se utilizó para calcular métricas de citación como el número total de citas, citas por año, índice h, g, hI, norm, hI, annual y hA.
Bibliometrix (R) se aplicó para el análisis de evolución temática y la distribución global de la producción científica.
Configuración de VOSviewer:
Tipo de análisis: coocurrencia.
Unidad de análisis: keywords.
Método de conteo: full counting.
Mínimo número de ocurrencias: 5.
Número máximo de keywords seleccionadas: 1000.
Se calcularon los indicadores de impacto más comunes:
Índice h: mide la productividad y el impacto global de los autores.
Índice m: ajusta el índice h en función de los años transcurridos desde la primera publicación, útil para identificar investigadores emergentes.
Índice g: pondera el impacto acumulado de la obra de un autor al ordenar sus publicaciones por número de citas.
Estos indicadores se complementaron con métricas de colaboración internacional, tasas de crecimiento anual, productividad por autores y análisis de palabras clave, con el fin de caracterizar integralmente el perfil bibliométrico global sobre la inteligencia artificial aplicada a las enfermedades crónicas no transmisibles indexadas en Scopus.
El flujo de trabajo bibliométrico aplicado en esta investigación, que abarca desde la normalización de metadatos hasta la visualización relacional, constituye un protocolo validado para la gestión de la evidencia. Dicho protocolo se propone como una competencia técnica transferible a los programas de formación de posgrado, permitiendo auditar la calidad de la ciencia que sustenta su práctica clínica.
No se requirió aprobación de un comité de ética, ya que se trabajó exclusivamente con información secundaria de acceso público, sin datos personales ni sensibles. Se respetaron los principios de transparencia y responsabilidad científica conforme a la Declaración de Helsinki[2013] y las normas éticas de publicación científica.
Resultados
Se encontró una producción de 9181 documentos. A pesar de la juventud de las publicaciones (edad promedio de 1 año), el corpus ya ha acumulado 35961 citas, con una tasa de citación de 3.91 por documento como se muestra en la tabla 1 . El índice h de 47, considerando el cortísimo tiempo de ventana de citación, es excepcionalmente alto. El perfil de colaboración es notable, con una media de 6.04 coautores por documento y una tasa de colaboración internacional del 21.56 % ( tabla 1 ).
| Categoría | Métrica | Valor |
|---|---|---|
| Producción | Período de publicación | 2024 |
| Total de documentos | 9181 | |
| Fuentes (revistas, libros, etc.) | 2168 | |
| Tasa de crecimiento anual | 0 % (ventana de 1 año) | |
| Colaboración | Total de autores | 28752 |
| Apariciones de autores | 55483 | |
| Autores por documento (media) | 6.04 | |
| Colaboración internacional (%) | 21.56 | |
| Documentos de un solo autor | 268 | |
| Impacto | Total de citas | 35961 |
| Citas por documento | 3.91 | |
| Citas por documento por año | 1.96 | |
| Índice h | 47 | |
| Índice g | 66 | |
| Edad promedio de los documentos | 1 año |
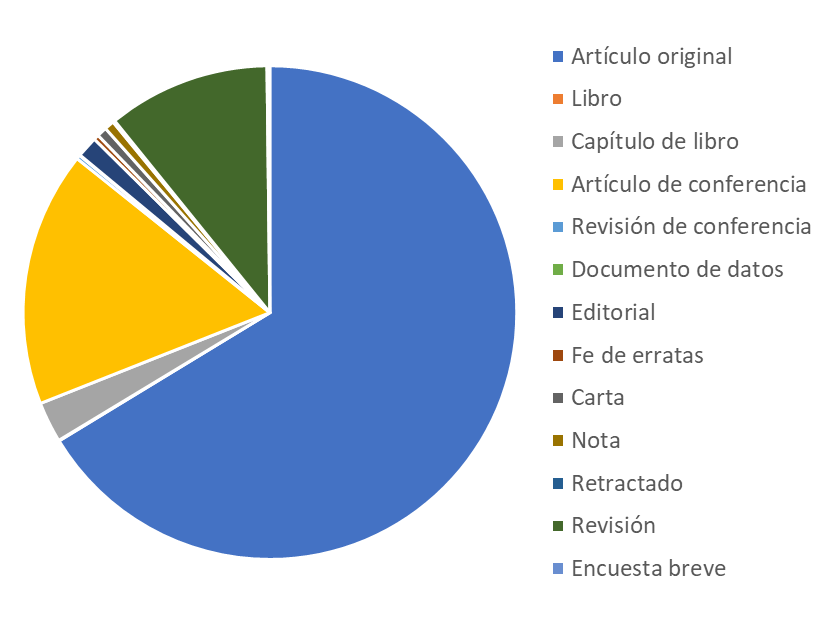
Respecto a la tipología de documentos, la gran mayoría de las publicaciones son artículos de investigación originales (6087 que representan el 66.3 %). Los artículos de conferencia (1536 que representan el 16.7 %) y las revisiones (977 que representan el 10.6 %) constituyen las categorías más significativas ( figura 1 ).
El análisis de productividad identificó a los investigadores más productivos, mostrado en la tabla 2 . Es notable como los autores con apellidos de origen chino (Wang Y, Zhang Y, Li Y) dominan el top de productividad, tanto en el recuento total como en el fraccionado ( tabla 2 ).
| Ranking | Autor (recuento total) | Artículos | Autor (recuento fraccionado) | Artículos |
|---|---|---|---|---|
| 1 | WANG Y | 304 | WANG Y | 46.1 |
| 2 | ZHANG Y | 235 | NA NA | 46.0 |
| 3 | LI Y | 215 | ZHANG Y | 33.9 |
| 4 | LI X | 198 | LI Y | 32.6 |
El mapa de colaboración internacional ( tabla 3 ) está claramente liderado por China, que es el país de afiliación del autor correspondiente en el 39 % de los documentos. India y Estados Unidos ocupan el segundo y tercer lugar, respectivamente. Países como Canadá, Australia y Francia muestran ratios de publicación internacional (MCP_Ratio) muy altos (por encima de 0.59).
| País | Artículos | Frecuencia | Publicaciones nacionales (SCP) | Publicaciones internacionales (MCP) |
|---|---|---|---|---|
| China | 3427 | 39.0 % | 3056 | 371 |
| India | 1429 | 16.3 % | 1229 | 200 |
| USA | 746 | 8.5 % | 716 | 30 |
| Italy | 254 | 2.9 % | 163 | 91 |
| Canada | 217 | 2.5 % | 82 | 135 |
El trabajo más citado en este corto período fue el de Huang et al.[2024] en Signal Transduction and Targeted Therapy, con 204 citas ( tabla 4 ). La lista de los más citados está dominada por publicaciones en revistas de alto impacto en oncología y medicina traslacional.
| Paper | DOI | Citas totales | Citas por año |
|---|---|---|---|
| HUANG Y, 2024, Signal Transduct. Target. Ther. | 10.1038/s41392-024-01745-z | 204 | 102 |
| SHAHUL A, 2024, NANA | 10.4018/979-8-3693-1335-0.ch007 | 152 | 76 |
| PRELAJ A, 2024, Ann. Oncol. | 10.1016/j.annonc.2023.10.125 | 130 | 65 |
| ZHANG Z, 2024, Nat. Rev. Clin. Oncol. | 10.1038/s41571-024-00892-0 | 120 | 60 |
| LI Q, 2024, Signal Transduct. Target. Ther. | 10.1038/s41392-024-01953-7 | 118 | 59 |
Las revistas más relevantes ( tabla 5 ) son una mezcla de publicaciones de acceso abierto de gran volumen (e.g., Frontiers in Oncology, Scientific Reports) y revistas especializadas en cáncer e inmunología.
| Fuente | Artículos |
|---|---|
| FRONTIERS IN ONCOLOGY | 177 |
| SCIENTIFIC REPORTS | 174 |
| CANCERS | 154 |
| FRONTIERS IN IMMUNOLOGY | 151 |
| LECTURE NOTES IN NETWORKS AND SYSTEMS | 96 |
El mapa de densidades de la figura 2 mostró las áreas de mayor concentración e intensidad investigadora. La zona más brillante (amarilla) se encuentra en el centro, alrededor de la intersección de "human", "machine learning", "diagnosis" y "deep learning". Otras áreas de alta densidad incluyen "prognosis" (especialmente en oncología) y "risk factors" para enfermedades crónicas.

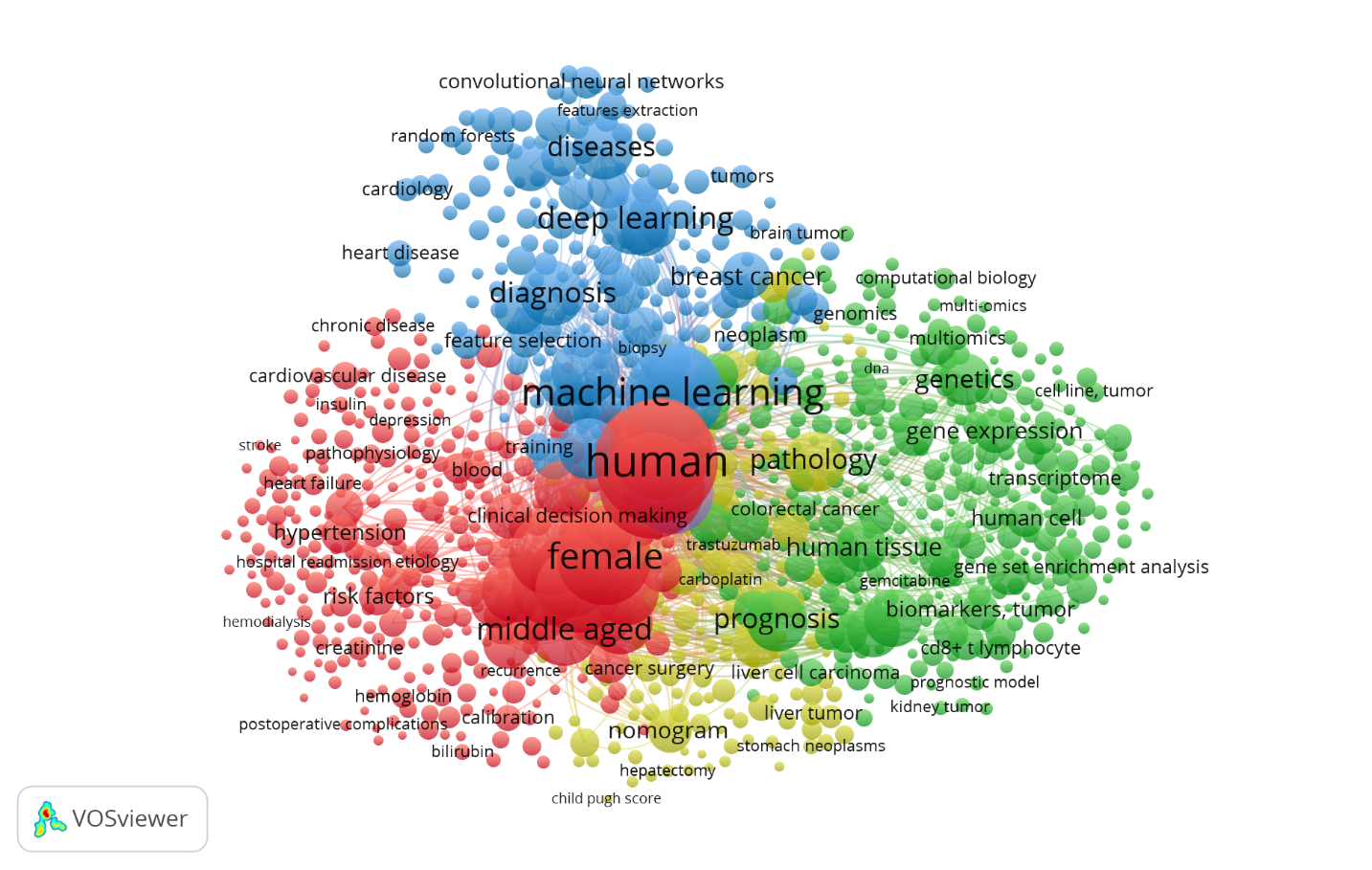
El grafo de coocurrencia de la figura 3 delineó clúster temáticos distintivos:
Clúster rojo: factores de riesgo y complicaciones clínicas. Este clúster se centra en la aplicación de la IA para analizar factores de riesgo y predecir complicaciones en enfermedades crónicas, especialmente cardiovasculares y renales. Términos clave: hypertension, cardiovascular disease, heart failure, postoperative complications, creatinine, hemoglobin, female, middle aged.
Clúster verde: genética y biología molecular. Este grupo se enfoca en la intersección entre la IA y la biomedicina fundamental, particularmente en oncología. Términos clave: genetics, gene expression, genomics, transcriptome, biomarkers, tumor, multi-omics, computational biology.
Clúster azul: aprendizaje automático y diagnóstico. Este es el cluster tecnológico central, dedicado a los algoritmos y metodologías de IA. Términos clave: deep learning, machine learning, diagnosis, convolutional neural networks, features extraction, random forests.
Clúster amarillo: pronóstico y oncología clínica. Este clúster se especializa en el uso de la IA para predecir la progresión de enfermedades y la supervivencia, con un fuerte énfasis en varios tipos de cáncer. Términos clave: prognosis, liver cell carcinoma, breast cancer, colorectal cancer, nomogram, recurrence, cancer surgery, trastuzumab.
Discusión
El alto volumen de producción científica observado en 2024, con más de nueve mil documentos y un índice h de 47, confirma la expansión acelerada de la IA en salud. Este crecimiento se alinea con informes recientes que destacan un aumento exponencial de publicaciones y la diseminación de resultados preliminares a través de preprints en 2023–2024.[8] Aunque esta magnitud impulsa la innovación, también genera heterogeneidad metodológica y ruido, ya que muchos estudios se limitan a validaciones internas, sin evaluación multicéntrica robusta. Esta limitación reduce la generalizabilidad de los hallazgos y plantea la necesidad de promover consorcios internacionales que desarrollen conjuntos de datos más representativos.[9] Asimismo, complementar la bibliometría con revisiones sistemáticas y análisis críticos ayudaría a discernir la calidad frente a la cantidad, evitando sobrevalorar tendencias pasajeras basadas únicamente en citaciones tempranas.[10]
Esta eclosión de literatura técnica evidencia una brecha pedagógica: la necesidad de integrar la alfabetización de datos en el currículo médico. Los resultados demuestran que la complejidad de los modelos predictivos actuales sobrepasa el análisis intuitivo tradicional, exigiendo un nuevo modelo de razonamiento clínico donde el cirujano o internista actúecomo gestor de información crítica, capaz dee interpretar los sesgos y alcances de la IA antes de su aplicación al paciente.
La concentración temática en oncología refleja la disponibilidad de imágenes digitales e información multi-ómica que favorecen el entrenamiento de modelos de aprendizaje profundo. En 2024, los artículos más citados se centraron en diagnóstico histopatológico, segmentación de tumores y predicción de respuesta terapéutica, campos donde la IA ha mostrado un rendimiento notable.[11] Sin embargo, revisiones sistemáticas y meta-análisis recientes subrayan la heterogeneidad metodológica, la falta de validaciones externas consistentes y la limitada replicabilidad de los resultados.[12] Aunque la oncología se beneficia de un entorno rico en datos y biomarcadores, existe el riesgo de desatender otras ECNT que concentran elevada carga global, como la diabetes o la enfermedad cardiovascular.[13] Para evitar sesgos en la agenda científica, es crucial diversificar datasets y dirigir recursos hacia múltiples patologías, para garantizar que la expansión de la IA en salud sea equitativa y de impacto poblacional amplio.[14]
Los patrones de colaboración internacional muestran una tasa de coautoría elevada, con una media de seis autores por artículo y un 21.6 % de colaboración multinacional. Este indicador revela un campo multidisciplinario en expansión, pero también refleja desigualdades geográficas: China concentró casi el 40 % de la producción, seguida de India y Estados Unidos. Aunque este liderazgo destaca capacidad de inversión e infraestructura, plantea interrogantes sobre la diversidad de datos y la generalización de modelos.[15] La dependencia de poblaciones locales puede reproducir sesgos y limitar aplicabilidad en otros contextos, por lo que se recomienda fortalecer consorcios globales y programas de datos abiertos que favorezcan validación en poblaciones diversas.[16] Asimismo, iniciativas editoriales que promuevan análisis por subgrupos y reportes estandarizados de diversidad podrían equilibrar la influencia geográfica y mejorar la equidad en la adopción clínica de la IA.[17]
La tipología documental encontrada en 2024 muestra predominio de artículos originales (66.3 %), seguidos por conference papers y revisiones. Esta distribución evidencia un ecosistema activo que combina difusión de resultados preliminares en congresos con publicaciones más elaboradas en revistas revisadas por pares. Los trabajos en conferencias cumplen un papel crucial en la circulación temprana de prototipos, aunque muchos de ellos no alcanzan madurez suficiente para la práctica clínica.[18] En este sentido, la proporción significativa de conference papers exige cautela, ya que su impacto bibliométrico no necesariamente se traduce en impacto clínico. Para mejorar la reproducibilidad y robustez, se requieren guías editoriales que establezcan estándares mínimos de validación y transparencia metodológica, incluso para comunicaciones preliminares.[19] Esto, favorecería la construcción de evidencia progresiva y confiable y fortalecería el tránsito de innovaciones desde el prototipo académico hasta la implementación en entornos clínicos reales.[20]
Metodológicamente, el uso combinado de bibliometrix, VOSviewer y CiteSpace en este estudio demostró la utilidad de integrar distintas herramientas de análisis para obtener una visión más sólida del campo. Mientras VOSviewer facilita mapas de co-ocurrencia y densidad, CiteSpace identifica brotes de palabras clave y nodos de centralidad, y bibliometrix ofrece métricas cuantitativas reproducibles en R. La convergencia de resultados entre programas aporta confianza a las interpretaciones, revelando clústeres temáticos robustos como diagnóstico ML/DL, oncología, multi-ómicas y factores de riesgo.[21] No obstante, la validez de los hallazgos depende de decisiones de limpieza de datos, selección de términos y parámetros de visualización, por lo que la transparencia metodológica debe institucionalizarse. Documentar criterios de inclusión, versiones de software y parámetros técnicos debería ser un requisito editorial para garantizar reproducibilidad y comparabilidad entre estudios bibliométricos de IA en salud.[22]
Aunque el índice h=47 y las más de 35000 citas indican un impacto académico considerable, las métricas bibliométricas reflejan influencia en la literatura, no necesariamente en la práctica clínica. Revisiones recientes de la Administración de Alimentos y Medicamentos de los Estados Unidos (FDA, por sus siglas en inglés Food and Drug Administration) y estudios de metaanálisis han señalado que muchos modelos de IA con alto impacto científico carecen de validación en entornos reales o de aprobación regulatoria.[23] Esto pone de manifiesto la necesidad de estudios prospectivos que midan desempeño en la práctica diaria, así como evaluaciones de coste-efectividad e impacto en resultados de salud. La verdadera consolidación de la IA en medicina dependerá de su traducción a protocolos clínicos robustos y seguros, con participación de pacientes y profesionales en procesos de evaluación. Sin estas evidencias, el entusiasmo bibliométrico puede sobredimensionar logros aún inmaduros para la atención sanitaria.[24]
En materia regulatoria y de transparencia, 2024 evidenció avances con la publicación de guías de la FDA para planes de cambio predeterminado en modelos de IA médica. Estas normativas buscan garantizar seguridad y eficacia en modelos que evolucionan mediante actualizaciones periódicas, un desafío clave frente a la naturaleza adaptativa del aprendizaje automático.[25] Además, iniciativas como las model cards proponen mecanismos estandarizados para comunicar datos de entrenamiento, limitaciones y desempeño, favoreciendo la comprensión por parte de clínicos y reguladores.[26] Sin embargo, la adopción de estas prácticas aún es desigual, y la falta de auditorías externas independientes limita la confianza. Consolidar marcos regulatorios globales y promover la obligatoriedad de herramientas de transparencia será fundamental para mejorar la gobernanza y credibilidad de la IA aplicada a la salud.[27]
Finalmente, la gobernanza de datos e interoperabilidad son pilares para la sostenibilidad del campo. Sin infraestructuras seguras que garanticen anonimización, armonización y acceso equitativo, la validación multicéntrica seguirá siendo limitada y concentrada en países con mayores recursos. Experiencias recientes de consorcios internacionales han demostrado que acuerdos de interoperabilidad y estándares comunes de metadatos facilitan investigación colaborativa y auditorías de equidad a gran escala.[28] Este tipo de gobernanza es crítico no solo para reproducibilidad, sino también para confianza pública y ética en el uso de IA en salud. Avanzar hacia infraestructuras globales permitirá que el potencial de la IA se traduzca en beneficios tangibles y equitativos, evitando una concentración excesiva de capacidades y resultados en unos pocos centros de excelencia con recursos privilegiados.[29]
Los resultados de este estudio poseen una alta generalizabilidad, dado que se basan en datos obtenidos de la base de datos Scopus, una de las fuentes más amplias y representativas de la literatura científica internacional. Los hallazgos ofrecen una visión global y actualizable de las tendencias en investigación sobre inteligencia artificial aplicada a las enfermedades crónicas no transmisibles, lo que permite extrapolar patrones generales y orientar futuras investigaciones en contextos diversos. Entre las principales limitaciones del estudio se encuentra la utilización exclusiva de la base de datos Scopus, lo que podría generar un sesgo de cobertura al excluir publicaciones indexadas en otras fuentes relevantes como Web of Science o PubMed. Además, la búsqueda se restringió a documentos con acceso en dicha base y puede haberse visto afectada por la variabilidad en la indexación de palabras clave y la disponibilidad de metadatos. Finalmente, al tratarse de un análisis bibliométrico, los resultados dependen de la calidad y actualización de los registros.
El análisis bibliométrico del corpus 2024 revela un campo en rápida expansión, con predominio de investigaciones en oncología, alta colaboración pero concentración geográfica y variabilidad metodológica que limita la reproducibilidad; para traducir los avances técnicos en beneficios clínicos equitativos se requieren validación externa multicéntrica, estandarización de protocolos y reportes, auditorías algorítmicas, gobernanza de datos, inversión en infraestructura y capacitación multidisciplinaria. Es esencial que reguladores, financiadores y editores exijan transparencia en modelos, análisis por subgrupos y estudios de implementación que midan desenlaces clínicos y equidad; solo con esa articulación la innovación en IA podrá consolidarse como herramienta efectiva y segura al servicio de la salud poblacional sin aumentar desigualdades.
Conclusiones
El presente estudio cienciométrico no solo documenta el estado del arte de la IA en las ECNT, sino que fundamenta la necesidad de transitar hacia un sistema de soporte a la decisión clínica basado en evidencia de alto impacto. Los hallazgos aquí presentados sirven de premisa para el desarrollo de metodologías educativas que armonicen el juicio clínico humano con las métricas de precisión tecnológica, optimizando así la seguridad del paciente y la eficiencia diagnóstica.
REFERENCIAS BIBLIOGRÁFICAS
- Senthil R, Anand T, Sree Somala C, Mani Saravanan. K. Bibliometric analysis of artificial intelligence in healthcare research: Trends and future directions. Future Healthcare Journal [Internet]. 2024 [citado 10 Sep 2025]; 11(3):e100182. Disponible en: https://www.sciencedirect.com/science/article/pii/S2514664524015728
- Xie Y, Zhai Ya, Luis G. Evolution of artificial intelligence in healthcare: a 30-year bibliometric study. Front. Med. 2025 [citado 10 Sep 2025]; 11:1505692. Disponible en: https://doi.org.10.3389/fmed.2024.1505692
- Hussain W, Mabrok M, Gao H, Rabhi FA, Rashed EA. Revolutionising healthcare with artificial intelligence: A bibliometric analysis of 40 years of progress in health systems. Digital health. 2024 [citado 10 Sep 2025]; 10:20552076241258757. Disponible en: https://doi.org/10.1177/20552076241258757
- Lin M, Lin L, Lin L, Lin Z, Yan X. A bibliometric analysis of the advance of artificial intelligence in medicine. Front Med [Internet]. 2025 [citado 10 Sep 2025]; 12:1504428. Disponible en: https://pmc.ncbi.nlm.nih.gov/articles/PMC11885233/
- Ebad SA, Alhashmi A, Amara M, Miled AB, Saqib M. Artificial Intelligence-Based Software as a Medical Device (AI-SaMD): A Systematic Review. Healthcare. 2025 [citado 01 Oct 2025]; 13(7):817. Disponible en: https://doi.org/10.3390/healthcare13070817
- Gilbert S, Adler R, Holoyad T, Weicken E. Could transparent model cards with layered accessible information drive trust and safety in health AI? npj Digit. Med. 2025 [citado 01 Oct 2025]; 8(124):1-5. Disponible en: https://doi.org/10.1038/s41746-025-01482-9
- Chamorro K, Calderón Álvarez R, Carvajal Ahtty M, Quinga M. Comprehensive bibliometric analysis of advancements in artificial intelligence applications in medicine using Scopus database. Franklin Open. 2025 [citado 01 Oct 2025]; 10(1):e100212. Disponible en: https://doi.org/10.1016/j.fraope.2025.100212.
- Awasthi R, Mishra S, Grasfield R, Maslinski J, Mahapatra D, Cywinski JB, Khanna AK et al. Artificial Intelligence in Healthcare: 2023 Year in Review. medRxiv. 2024 [citado 02 Oct 2025]; 2(28):24303482. Disponible en: https://doi.org/10.1101/2024.02.28.24303482
- Palacios Núñez ML, Toribio López A, Deroncele Acosta A. Innovación educativa en el desarrollo de aprendizajes relevantes: una revisión sistemática de literatura. Revista Universidad y Sociedad [Internet]. 2021 [citado 02 Oct 2025]; 13(5):134-145. Disponible en: http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S2218-36202021000500134&lng=es&tlng=es.
- Aldousari E, Dennis Kithinji D.Artificial intelligence and health information: A bibliometric analysis of three decades of research. Health Informatics Journal. 2024 [citado 02 Oct 2025]; 30(3):19. Disponible en: https://doi.org/10.1177/14604582241283969
- Reis TC. Deep learning in oncology: Transforming cancer diagnosis. Lancet Oncol [Internet]. 2025 [citado 03 Oct 2025]; 5(2): e100171. Disponible en: https://www.researchgate.net/publication/389006657_Deep_Learning_in_Oncology_Transforming_Cancer_Diagnosis_Prognosis_and_Treatment
- Li H, Qin J, Li Z, Ouyang R, Chen Z, Huang S et al. Systematic review and meta- analysis of deep learning for MSI- H in colorectal cancer whole slide images.npj Digital Medicine [Internet]. 2025 [citado 04 Oct 2025]; 8(1):456. Disponible en: https://www.nature.com/articles/s41746-025-01848-z
- Yang H, Yang M, Chen J, Yao G, Zou Q, Jia L. Multimodal deep learning approaches for precision oncology: a comprehensive review, Briefings in Bioinformatics [Internet]. 2025 [citado 04 Oct 2025]; 26(1):e699. Disponible en: https://academic.oup.com/bib/article/26/1/bbae699/7942793
- Sartori F, Codicèt F, CaranzanoI, Rollo C, Birolo G, Fariselli P et al. Deep learning applications in genomics and cancer classification. Genes [Internet]. 2025 [citado 05 Oct 2025]; 16(6):648. Disponible en: https://www.mdpi.com/2073-4425/16/6/648.
- Gómez Velasco NY; Ayala Montoya LF, Gómez Velasco NS. Panoramas de producción y redes de colaboración científica. Indicadores y comparativos. Suramérica y otros países. Revista Historia de la Educación Latinoamericana [Internet]. 2022 [citado 05 Oct 2025]; 24(39)107-126: . Disponible en: https://www.redalyc.org/journal/869/86975367006/html/
- Torres Pérez ML. Salud digital: Retos y Oportunidades en la Atención Médica. Revista Internacional del Instituto de Pensamiento Liberal [Internet]. 2025 [citado 06 Oct 2025]; 2 (3):224-249. Disponible en: https://scholar.google.com/scholar?hl=es&as_sdt=0%2C5&as_ylo=2021&q=influencia+geogr%C3%A1fica+y+mejorar+la+equidad+en+la+adopci%C3%B3n+cl%C3%ADnica+de+la+IA+&btnG=#d=gs_qabs&t=1759894615206&u=%23p%3DBwR8haGacRwJ
- Sandoval Salgado VJ. Impacto de la Inteligencia Artificial en la Medicina Moderna. SARTIN [Internet]. 2024 [citado 07 Oct 2025]; 1(2):15-31. Disponible en: https://revistasapiensec.com/index.php/Sapiens_in_Artificial_Intelligen/article/view/33
- Arias Odón F. Investigación documental, investigación bibliométrica y revisiones sistemáticas. REDHECS [Internet]. 2023 [citado 07 Oct 2025]; 31(22): 9-28. Disponible en: https://www.researchgate.net/publication/378857493_Investigacion_documental_investigacion_bibliometrica_y_revisiones_sistematicas
- Du Q, Zhao R , Wan Q , Li S, Li H, Wang D. Protocol for conducting bibliometric analysis in health sciences. Protocolos STAR [Internet]. 2024 [citado 08 Oct 2025]; 5(3):e103269. Disponible en: https://www.sciencedirect.com/science/article/pii/S2666166724004349
- Koo TH, Zakaria AD, Ng JK, Leong XB. Systematic Review of the Application of Artificial Intelligence in Healthcare and Nursing Care. Malays J Med Sci [Internet]. 2024 [citado 08 Oct 2025]; 31(5):135-142. Disponible en: https://pmc.ncbi.nlm.nih.gov/articles/PMC11477473/
- Arruda H, Silva ER, Lessa M, Proença D Jr, Bartholo R. VOSviewer and Bibliometrix. J Med Libr Assoc [Internet]. 2022 [citado 08 Oct 2025]; 110(3):392-395. Disponible en: https://pubmed.ncbi.nlm.nih.gov/36589296/
- CiteSpace v6.3.R1. SourceForge [Internet]. 2024 [citado 09 Oct 2025]; Disponible en: https://sourceforge.net/projects/citespace/.
- FDA. AI/ML-enabled Medical Devices List. 2024–2025. [Internet] 2025 [citado 09 Oct 2025]; Disponible en: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices
- Legesse Jimma B. Artificial intelligence in healthcare: Al bibliometric analysis.Telematics and Informatics Reports [Internet]. 2023 [citado 09 Oct 2025]; 9(1): e100041. Disponible en: https://www.sciencedirect.com/science/article/pii/S2772503023000014
- Joshua O, Sager L, Band JM. FDA finalizes guidance on predetermined change control plans for AI-enabled devices. Ropes & Gray [Internet]. 2024 [citado 09 Oct 2025]. Disponible en: https://www.ropesgray.com/en/insights/alerts/2024/12/fda-finalizes-guidance-on-predetermined-change-control-plans-for-ai-enabled-device
- Flores de Valgas BA, Orquera MF, Acosta BF, Dambrosio GP. Diseño de un Balanced Score Card para la evaluación de la percepción del éxito en la innovación en las universidades públicas ecuatorianas. Revista Espacios. 2024 [citado 10 Oct 2025]; 45(4): 54-72. Disponible en: https://doi.org/10.48082/espacios-a24v45n04p05
- Lund B, Orhan Z, Mannuru NR, Kumar Bevara RV, Porter B, Kasi Vinaih M, Bhaskara P. Standards, frameworks, and legislation for artificial intelligence (AI) transparency. AI Ethics [Internet]. 2025 [citado 10 Oct 2025]; 5(1):3639-3655. Disponible en: https://link.springer.com/article/10.1007/s43681-025-00661-4#citeas
- Ding X, Lu D, Wei R, Zhu F. Knowledge mapping of online healthcare: An interdisciplinary visual analysis using VOSviewer and CiteSpace. Digit Health [Internet]. 2025 [citado 10 Oct 2025]; 11:20552076251320761. Disponible en: https://doi.org/10.1177/20552076251320761
- Elias MA, Faversani LA, Moreira JAV, Masiero AV, Cunha NV da. Artificial intelligence in health and bioethical implications: a systematic review. Rev Bioét 2023 [citado 10 Oct 2025]; 31:e3542PT. Disponible en: https://doi.org/10.1590/1983-803420233542PT
CONTRIBUCIÓN DE AUTORÍA
EAHG: Conceptualización; Análisis formal; Investigación; Metodología; Administración del proyecto; Recursos; Supervisión; Validación; Visualización; Redacción – borrador original; Redacción – revisión y edición
AJFQ: Análisis formal; Investigación; Metodología; Software; Redacción – borrador original; Redacción – revisión y edición
DMH: Curación de datos; Investigación; Redacción – borrador original; Redacción – revisión y edición
DMG: Investigación; Redacción – borrador original; Redacción – revisión y edición
SMRL: Redacción – borrador original; Redacción – revisión y edición
CONFLICTOS DE INTERÉS
Los autores declaran que no existen conflictos de intereses.
FINANCIAMIENTO
Los autores no recibieron financiación para el desarrollo del presente artículo.
